
Today's Best Vector Database
Feb 1, 2024
•
Mike Depinet
There are lots of vector database solutions on the market, from Postgres extensions like pgvector to standalone open-source options like Weaviate to black-box hosted options like Pinecone. This blog post pits several of these head-to-head to explain why Fixie migrated from the very popular Pinecone vector database to a relative newcomer.
Background
Vector Databases and RAG
As large language models (LLMs) took the world by storm in 2023, retrieval augmented generation (RAG) quickly became a best practice for making models much more likely to generate true information (that is, to avoid “hallucination” in popular parlance). The key element of effective RAG is rapidly identifying which bits of text from a large body of human-approved sources should be added to the model’s context window to best ground the result. Often this works by determining the semantic similarity between a user’s query and all the bits of text we have available to choose from.
In years past, we might construct some notion of semantic similarity (i.e. relevance) based on keyword matching, but these days we can do much better. At risk of oversimplifying, LLMs give us a way to transform text into a vector through a process called embedding. Cohere published a nice intro to embedding for the curious, but the key idea is that because LLMs are pretty good at understanding text, they’ll create similar vectors for text with similar meanings (semantics). This provides us a more general definition of semantic similarity - two bits of text are semantically similar when the vectors produced for them by an LLM are close together (where “close together” refers to cosine similarity for our purposes). When searching over a large document set (a corpus), we still need to do tons of these comparisons quickly though and that’s where a vector database (VDB) comes in.
Prior to serving user requests, we identify all the bits of text from the corpus we might want to shove in our LLM’s context window and turn those into vectors. We store these in a VDB and create an index so that when a query comes in, we can quickly embed it and retrieve the nearest vectors to figure out which information to surface.
If you’d like to see a working example, you can use Fixie to ingest a public website or upload your own documents and then answer questions about the content.
Fixie History and Motivation
Like many early-stage AI startups in 2023, Fixie started off using LangChain. At the time, Pinecone had an easy integration route and provided the leading edge in terms of quality and latency. While other options also existed, Pinecone seemed like the path of least resistance. However, as we started to scale up and push past demo implementations it was clear that LangChain was holding us back (see footnote 1). Ultimately we built our own corpus service to provide the scale and speed we wanted when searching thousands of documents, all the while living with Pinecone.
Our corpus service turned out to be fairly popular and as usage grew we had to add more “pods” (read “servers”) to our Pinecone instance several times. Unfortunately as we approached the end of 2023, we were approaching the maximum capacity of a Pinecone instance - adding more pods was no longer an option. 😨 This forced us to consider alternatives.
Let the Games Begin!

Given our position and where we add value, we wanted a VDB that was going to provide the scale, latency, and accuracy we’ll need well into the future. And of course we didn’t want to pay more than necessary for it!
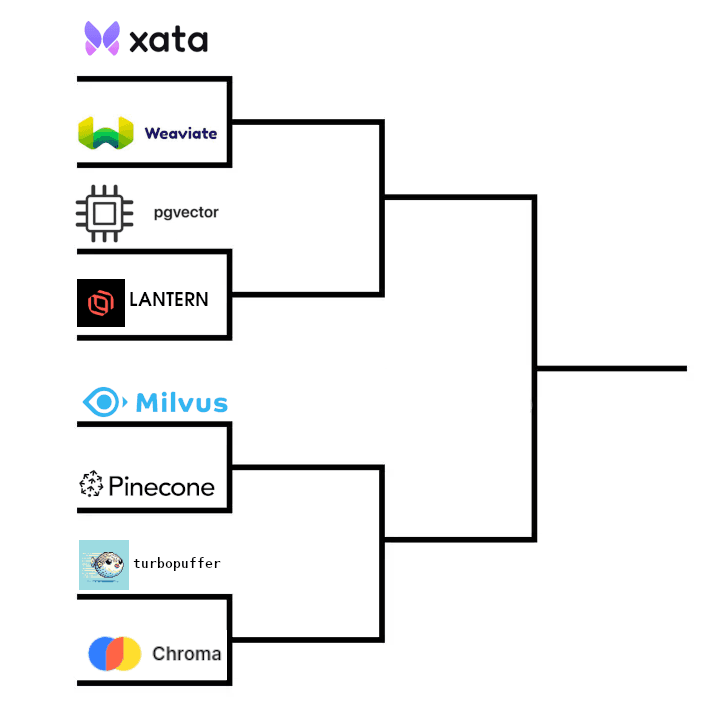
We considered 8 alternatives, which this blog pits head-to-head for your entertainment (see footnote 2). This could be a 64 competitor bracket at this point (see e.g. this list) but we narrowed it down to 8 we thought were promising for us to investigate. If you’re interested in a full March Madness blog or have other competitors you’d like to see compared, let us know!
Quarter Finals
Let’s meet our competitors and start to narrow the field!
Xata versus Weaviate
Xata is a serverless, hosted database platform with a rich feature set. We only evaluated the offering as a VDB, but it’d likely be a stronger competitor for someone who also needed a relational database.
Weaviate is an open source VDB implementation with a hosted option. Its schema setup is pretty different from all the other competitors.
Both these options seem like they’d scale to meet our needs just fine. The deciding factor in this matchup is Weaviate’s choice to wrap the embedding process. This may be a neat feature for someone getting started, but it wouldn’t fit well with Fixie’s existing corpus service infrastructure. We were also skeptical of this approach’s performance given the latency savings we previously got by storing our text content outside of Pinecone. Xata kicks things off with a convincing round 1 win.

PGVector versus Lantern
PGVector is an open source Postgres extension that allows adding and indexing vectors alongside all your existing relational data. Fixie strongly considered switching from Pinecone to PGVector when we built our corpus service because of the easy consistency we’d get from updating vectors transactionally with related data.
Lantern is also an open source Postgres extension. It promises much faster index creation than PGVector. It also interoperates with PGVector data for users considering a switch.
PGVector wins round 2 on a technicality. Fixie’s existing postgres instance is hosted by Google Cloud SQL where PGVector is available but Lantern is not. While Lantern has its own hosting option, we weren’t interested in migrating our non-vector data and moving only our vector data would undermine the main draw of a Postgres extension, namely transactional updates.
Post competition update: Lantern Cloud now has special support for migrating from Pinecone. This drop was too late for Fixie, but it might be a nice bonus for anyone else making this decision!

Milvus versus Serverless Pinecone
Zilliz provides a hosted option for the open source Milvus VDB.
Pinecone gave us very early access to their serverless offering, which is now in beta. This promised to alleviate our scale and maintenance concerns while simultaneously reducing our cost.
Using Zilliz’s own pricing calculator, it’d cost us as much as traditional Pinecone without providing any obvious advantages. Serverless Pinecone takes round 3.

Turbopuffer versus Chroma
Turbopuffer is a bare metal hosted VDB offering built from first-principles for maximum performance.
Chroma is a popular open source option for VDBs. We didn’t find a hosted offering. At the time we were looking, the latest v0.4 release was the first one focused on productionization, suggesting a hosted offering is likely in the near future but may have some road bumps for early adopters.
Chroma isn’t quite ready for prime time from our perspective. We also weren’t particularly interested in running our own service. Turbopuffer rounds out our semi-finals.

Semi-Finals
All our semi-finalists are worthy competitors, but who has the speed and precision to reach the finals!?
Xata versus PGVector

When evaluating PGVector’s characteristics, it’s important to consider what impact storing all your vectors in Postgres will have on your other data. (You could use separate databases of course, but then you’d forego the atomicity benefits.) For our evaluation and to make comparisons easy, we assumed a modest 100GB database running with 4 vCPUs and 16GB of ram with 20GB and 25% of connections set aside for non-vector data. While we did initially store vectors in Postgres while building our corpus service, we never queried them in a prod-like environment so a lot of our scale and latency expectations are based on non-vector data. Take them with a grain of salt. Supabase also has a helpful article specifically comparing Pinecone and PGVector for those interested in taking this path.
On the Xata side, we worked with the team to set up a test instance with a subset of our data from Pinecone. It was located in GCP in the same region as our own backends. Cost estimates are based on the 4M 1536 dimensional vectors we stored at the time.
While transactional updates would be awesome, we already decided not to move our non-vector data for now. That’s a point for PGVector, but we could get the same benefit from Xata in the future. The more important difference for us was that Xata is hands-off. For testing purposes we put all our test data in a single Xata database, but Xata would make it really easy to create a separate database for each of our corpora, which largely avoids the resource competition we’d get from PGVector in addition to making scaling trivial. (It also retains the level of atomicity we’d benefit from if we moved our other data in the future since all our mutations are within the scope of a single corpus.) Xata claims a spot in the finals!

Serverless Pinecone versus Turbopuffer

Pinecone comes out of the gate swinging with two options. Since Fixie has separate indexes for each of our customers’ corpora, it would be possible to add additional Pinecone instances and associate each corpus with one of them. This would be the fastest short-term option, but it would make our ongoing maintenance situation even worse (and it’d be even more expensive). Alternatively we could go serverless, which would resolve a lot of our scale and maintenance concerns. But wait! Pinecone suffers some major recoil damage by still requiring us to migrate all our data in order to use the serverless option!
Turbopuffer instead opts for a ghost strategy with its radical transparency. It probably has slightly lower recall than Pinecone right now, but that won’t be true in the near future and it made no difference in our testing. More importantly, there’s nothing theoretical about Turbopuffer. Its latency and scale are laid bare and easily satisfy our needs.
Pinecone put its best foot forward, but it was too little too late in this matchup. Turbopuffer knocks off the champ to advance to the finals!
Post competition update (3/28/24): Pinecone now has a handy cost estimator on their website. Based on that tool, $222/mo would have been a better estimate for Fixie's usage. One-click migrations from the traditional offering to serverless are also planned for April.

Finals - Xata versus Turbopuffer
It’s the moment you’ve all been waiting for - the finals are here! Let’s see what our competitors have left!
Turbopuffer jumps to a quick start, using its much greater speed to hit where it hurts. Xata counters with a flurry of features, but they’re all glancing blows in this VDB competition. Turbopuffer connects with a knockout blow in the cost department and this competition has come to its end. Turbopuffer wins!

Turbopuffer checked a lot of boxes to make it our final choice.
It’s inexpensive. TurboPuffer costs significantly less than any other hosted option (and might even be cheaper than self-hosted PGVector). We ended up upgrading all our users’ corpora to multi-vector chunks during our migration, doubling our vector count. Despite this and the atypically higher write traffic from the migration itself, our first bill was $19.37, more than 50x less than we were paying Pinecone.
It’s transparent. If there’s one link in this blog you click on, make it turbopuffer.com. There’s no other option here that will be as upfront with its performance characteristics.
It’s fast. While some other alternatives are in line with Turbopuffer here, it’d be challenging to do better without self-hosting.
It’s simple. Turbopuffer was super easy to integrate with. Complexity only gets surfaced where it makes a difference for performance (e.g. request and response compression). We integrated directly against the HTTP REST API, but there’s a Python client available now too.
It’s improving. Since we started our evaluation, Turbopuffer has further cut its cold query latency in half and has added support for arbitrary string IDs. Their roadmap is also published on their website.
Turbopuffer won’t be the right fit for everyone. There are features it lacks right now (e.g. deleting by filter and listing namespaces). That said, if you’re in the market for a no-nonsense VDB then you’ll be hard-pressed to beat Turbopuffer.
Footnotes
In particular, LangChain’s RAG implementation (at least at the time) always stored the full text for chunks in the VDB itself, which was not great for speed, scale, or cost. It also made options like associating multiple vectors with the same chunk infeasible. ↩
This is of course not how we really evaluated them, but hopefully it’s more fun to read about this way. 😄 ↩